Le but de cet article est de partager quelques astuces qui vont nous permettre de gagner du temps lors de la phase de développement des applications web en Java qui utilisent une base de données MySQL et un conteneur web Apache Tomcat, en utilisant comme principale outil Maven et Eclipse, ainsi que MySQL.
Plan :
- Installer Eclipse Mars, version Java EE sous windows.
- Création d’un projet Maven , dépendences et plugins.
- Plugin maven tomcat
- Intégration avec la base de données MySQL en utilisons une DataSource de Apache Tomcat.
- Installation d’Eclipse Mars :
Il faut installer au préalable la JDK, référez-vous à mon article sur l’installation de la JDK, puis allez sur le site :
Télécharger le fichier ZIP, puis décompresser le, placer à l’endroit de cotre choix, puis cliquer sur l’icône d’Eclipse.
Parmi les avantages d’utilisation de cette version est qu’elle intègre par défaut un certain nombre de plugins que nous allons utiliser pour développer une applications web java, parmi c’est plugin :
- WTP (Web Tools Platform) : http://www.eclipse.org/webtools/
- Maven Integration for Eclipse, donc on n’a pas besoin d’installer Maven pour pouvoir l’utiliser, avec cette version.
Pour s’assurer que vous avez ces outils, il faut se rendre dans Eclipse, Help à About Eclipse , vérifier que vous avez wtp et m2e (comme sur le schéma suivant):
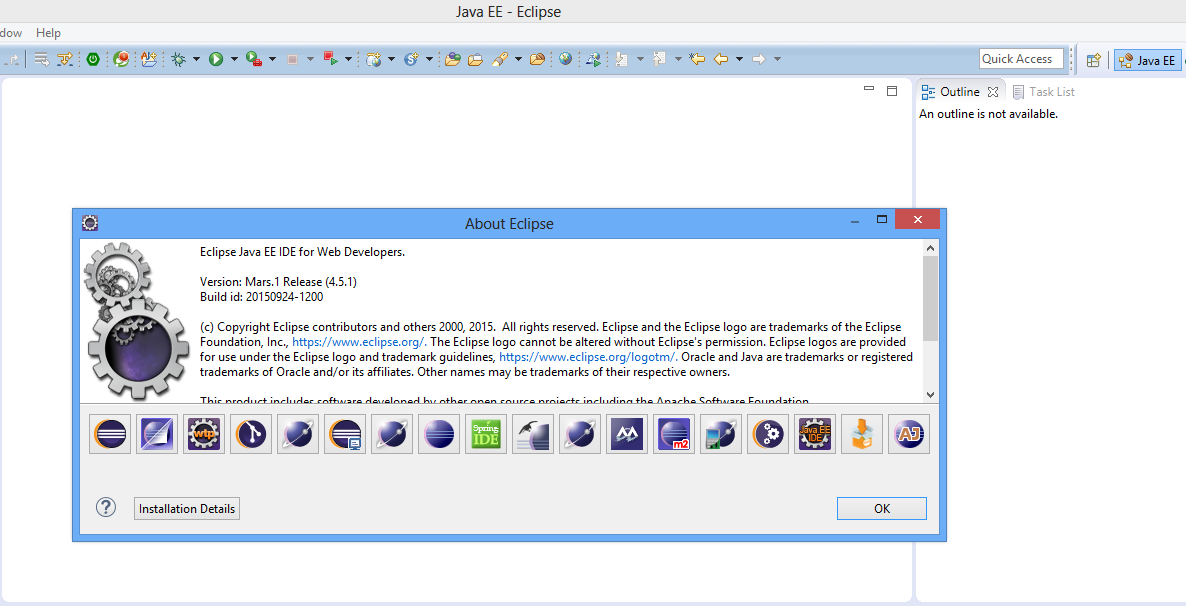
- Création d’un projet web dynamique avec Maven :
Vous faites un clic droit dans le projet Explorer, d’Eclipse, puis vous cliquez sur New, puis Project et vous sélectionnez Maven Projet comme dans la capture d’écran suivant :
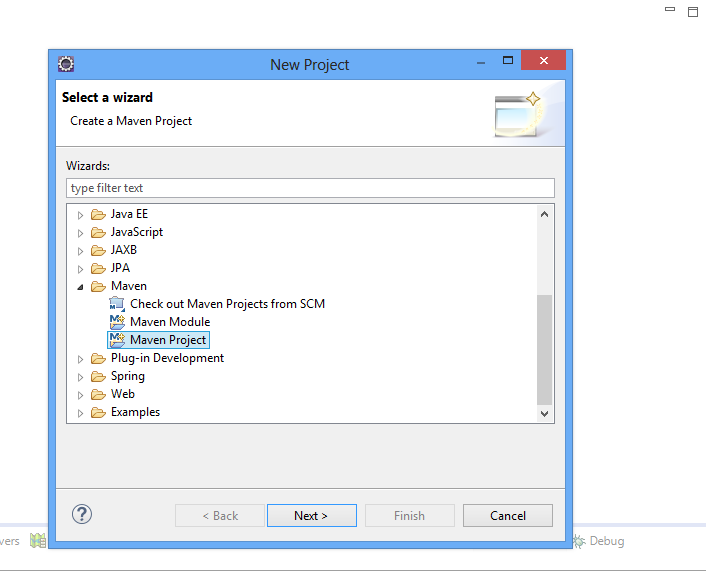
Puis, vous cliquez sur Next, et cochez : Create a simple projet (skip archetype selection) :
Puis, vous cliquez sur Next, après il faut renseigner le Group ID, l’Artifact Id, version et le Packaging :
C’est cette partie du POM (Projet Object Model) qui est un fichier XML, va permettre d’identifier votre projet.
GroupId : va permettre de connaitre la partie (entreprise, communauté, …) qui gère le projet. Pour les conventions du nommage on utilise ce qu’on appelle un reverse du domaine.
ArtifactId : est l’identifiant unique du composant qu’on développe au sein du GroupId .
Version : par défaut Majeur.Mineur.Correctif suivi du mot clé réservée de Maven SNAPSHOT.
Pour plus d’informations sur les conventions de nommage, voir le lien : https://maven.apache.org/guides/mini/guide-naming-conventions.html
- Exemple :
4.0.0 com.alphorm exemple-maven 0.0.1-SNAPSHOT war
J’attire votre attention sur le fait qu’il faut spécifier que le packaging et un war, puisque nous créons une application web dynamique.
Une fois que nous avons créé notre projet Maven on a le fichier pom.xml qui ressemble à ça :
Pour les besoins de notre projet web java, nous devons ajouter les dépendances suivant :
- servlet-api
- jsp-api
- jstl
- mysql-connector-java
Il y a plusieurs manières de le faire, mais on veut le faire directement à partir d’Elipse, pour cela il faut configure Eclipse pour qu’il charge les dépendances dont on a besoin directement du central repository, donc il faut aller dans le menu Window à Prefernces àMaven, puis il faut cocher la case : Download repository index updates on stratup :
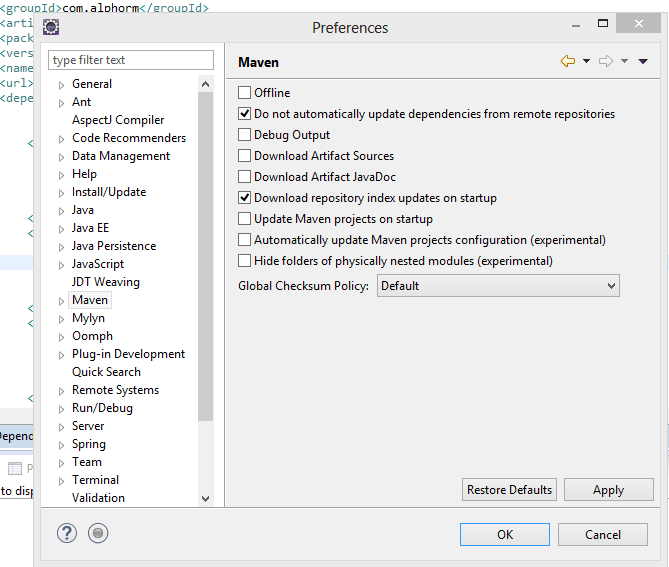
Par la suite il faut aller dans notre fichier pom.xml, puis on clique sur l’onglet Dependencies, puis Add…
Supposons que je veux ajouter JSTL pour une application qui utilise Servlet 3.0 à titre d’exemple.
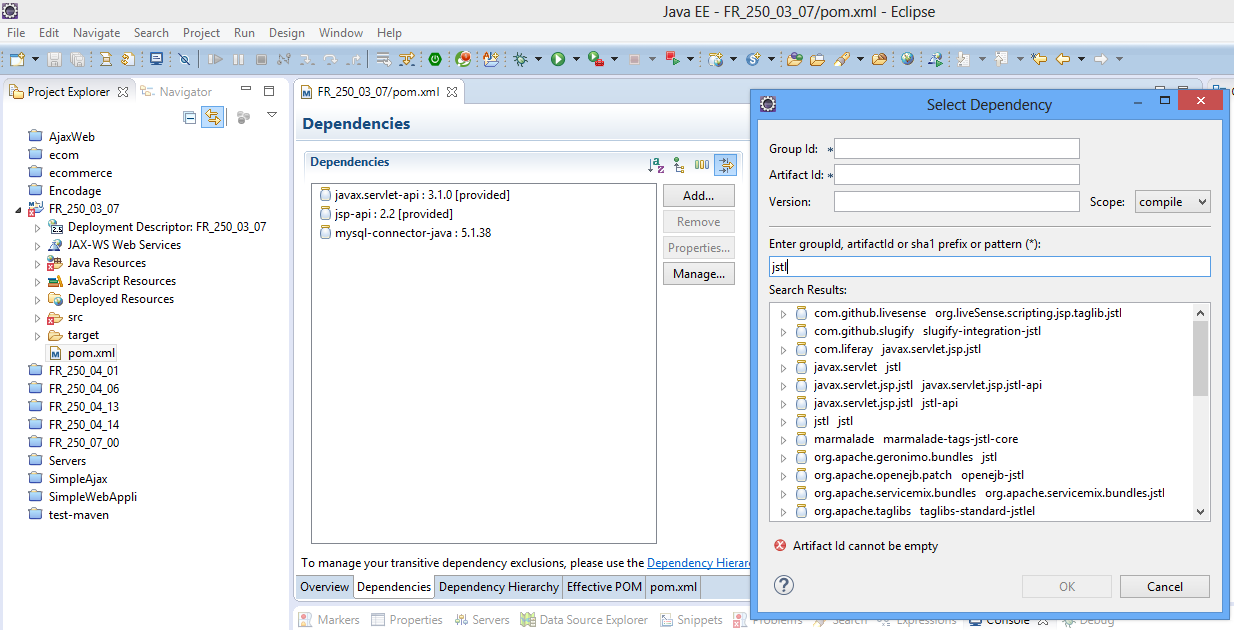
Puis, une fois qu’on ajoute notre dépendance on a la possibilité de modifier ces propriétés, typiquement je veux modifier le scope de ma dépendance à provided pour dire que cette dépendance sera fournie par notre environnement d’exécution qui tomcat dans notre cas, que nous allons devoir configurer par la suite à l’aide de Maven.
Afin d’arriver à notre but nous allons sélectionner notre dépendance, puis on clique sur propriétés… qui nous ouvre la fenêtre des dépendances comme suite :

Jusqu’à présent nous avons ajouté les dépendances dont on a besoin pour notre application, et nous souhaitons tester les Servlets et les JSP que nous avons développé. Donc on a besoin d’un conteneur web, qui va nous permettre de tester nos développements, il y a plusieurs solutions, mais nous avons choisi d’utiliser Maven pour intégrer le conteneur web Tomcat, maven nous propose d’ajouter des plugins, le pluign que nous allons utiliser est :
- tomcat7-maven–plugin
Pour l’ajouter, il faut sélectionner notre projet, clique droit, puis Maven –> Add Plugin

Nous avons ajouté notre conteneur web Tomcat à notre projet à travers les plugins Maven, maintenant nous allons pouvoir tester notre application, pour cela il faut crée un run configuration pour notre projet, il faut faire un clic droit sur notre projet, puis run As à Maven Build …, j’insiste sur les 3 points, vous aurez la fenêtre suivante :
Puis, au niveau du Goals il faut taper : tomcat7 :run
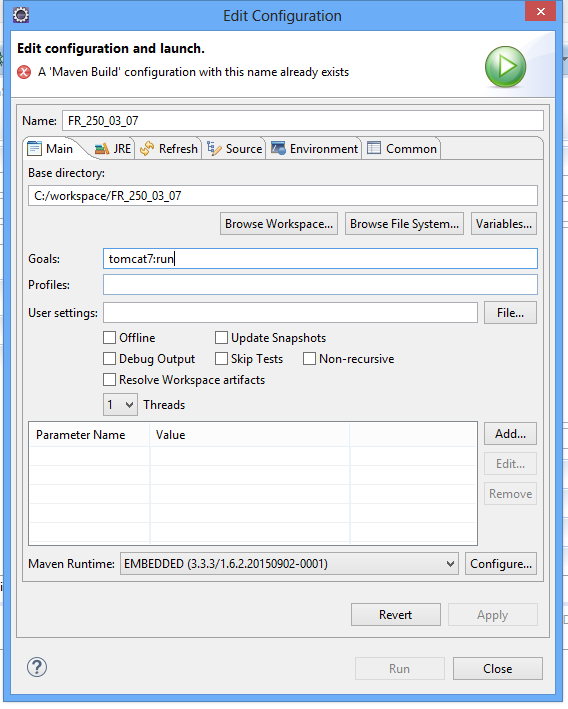
Par la suite, il sera disponible dans le Run AS … Avec le nom que vous avez choisi.
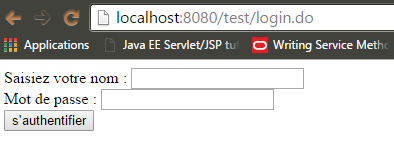
Si vous n’avez pas d’erreurs vous une console log pareil, avec un une adresse pour tester :

Je commence les tests et voici les résultats :
J’arrive à accéder à ma JSP de login :
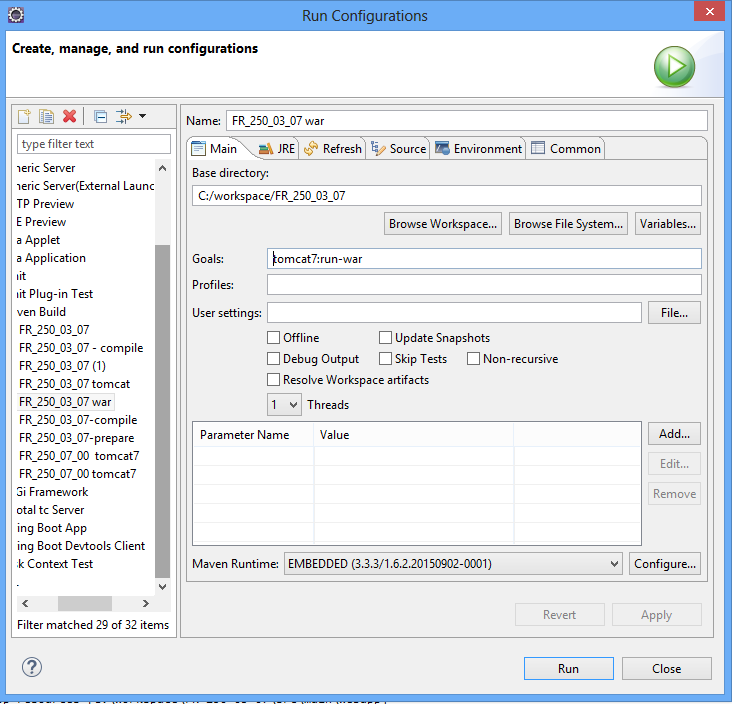
On plus d’un goal tomcat7 :run, il existe un ensemble d’autre goal, que vous pouvez trouver sur ce lien : https://tomcat.apache.org/maven-plugin-2.2/tomcat7-maven-plugin/plugin-info.html
Je vais démontrer l’utilisation d’un autre goal qui va nous permettre de créer un war (Web Archive) :
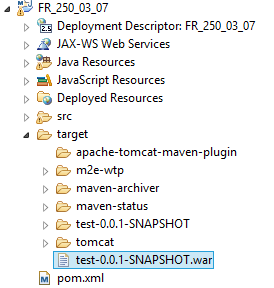
On exécute ce goal qui va créer le war de notre projet au niveau du répertoire target :
Utilisation d’une DataSource pour la gestion des connections (Pool de connection) :
Nous souhaitons se connecter à la base de données ou mes utilisateurs sont stocker, afin que je puisse les identifier. Plusieurs choix et solutions s’offre à nous, n’hésitez pas à voir le cours Java OCP (1Z0-804) le chapitre JDBC sur la plateforme Alphorm, qui explique les différents choix possibles :
C’est d’ailleurs un cours de très bonne qualité !
Revenons à nos moutons, le choix c’est porter sur l’utilisation d’un pool de connexion qui sera fourni par notre conteneur web Tomcat, à l’aide d’une DataSource qui sera localisé à l’aide d’un service de nommage (JNDI)qui va nous permettre de trouver notre ressource.
Pour voir le différence entre un DirverManager et une DataSource rendez-vous : http://docs.oracle.com/javase/7/docs/api/javax/sql/DataSource.html
Là aussi, on peut compter sur Maven pour aller très vite, cependant la configuration demande un peu de concentration.
Il nous faut :
- Une DataSource pour les pool de connexion (sera fournie par Tomcat)
- Pour la recherche il nous faut JNDI avec InitialContext
Nous commençons par configurer le plugin tomcat7-maven , dans notre fichier pom.xml on précisons le contextFile, qui contient le fichier context.xml :
org.apache.tomcat.maven tomcat7-maven-plugin 2.2 src/test/resources/context.xml
La création du fichier context.xml, il faut faire attention au ResourceLink le name doit être celui du Context:
Il faut aussi configurer le fichier web.xml, on ajoutons :
Connexion à la base de données MySQL jdbc_mabdd javax.sql.DataSource Container
Notre ressource est disponible il ne reste qu’à l’utiliser, et notre but est d’initialiser notre de pool de connexion avant le démarrage de notre application web, alors la solution c’est d’utiliser l’interface : ServletContextListener, voiçi un exemple :
@WebListener
public class InitialisationPoolDeConnexion implements ServletContextListener{
public void contextInitialized(ServletContextEvent sce) {
// Initaliser le contexte
Context contextInitial=null;
System.out.println("ouverture du : ServletContextListener");
try
{
contextInitial=new InitialContext();
if (contextInitial==null)
{
throw new Exception("Impossible de charger le contexte");
}
// Connexion JNDI
Context environnement=(Context)contextInitial.lookup("java:comp/env");
DataSource datasource=(DataSource)environnement.lookup("jdbc_mabdd");
if (datasource==null)
{
throw new Exception("Erreur lors du chargement du datasource");
}
// Sauvegarder le datasource dans le contexte de l'application
ServletContext servletContext=sce.getServletContext();
servletContext.setAttribute("datasource", datasource);
}
catch (Exception e)
{
System.out.println(e.getMessage());
}
finally
{
try
{
// On ferme le contexte
if (contextInitial!=null)
{
contextInitial.close();
}
}
catch (Exception e)
{
System.out.println("Erreur lors de la fermeture du contexte");
}
}
}
public void contextDestroyed(ServletContextEvent sce) {
System.out.println("Fermeture du Datasource");
}
Ainsi, nous avons pu voir comment accéder notre cycle de développement à l’aide de Maven pour créer un projet web dynamique, comment ajouter des dépendances et comment ajouter le plugin tomcat7-maven pour lancer notre serveur configurer une connexion avec la base de données en utilisant une DataSource pour créer un pool de connexion, sans installer tomcat, ni le configurer.




